Clustering K-means++ algorithm process
2025-02-12 18:25:52 167 1 Report 0
0

Login to view full content
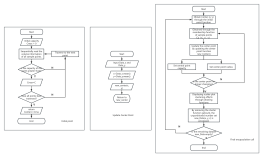
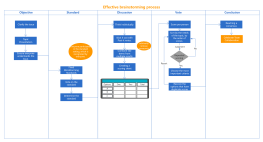
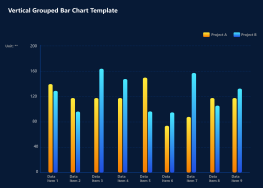
This flowchart illustrates the K-means++ algorithm process, a refined version of the traditional K-means clustering technique. It begins by randomly selecting a sample point as the initial cluster center and proceeds to determine whether the algorithm has converged or reached the maximum number of iterations. If not, it checks if the required number of K cluster centers has been established. Each sample is then assigned to the nearest cluster based on calculated distances. This systematic approach ensures efficient clustering by minimizing the initial selection bias, ultimately leading to improved accuracy and performance in data analysis.
Other creations by the author
Outline/Content
Output Cluster Division
Randomly select a sample point as the first initialized cluster center.
Is it converging or has it reached the number of iterations?
NO
Have K cluster centers been determined?
Assign each sample to the corresponding cluster with the smallest distance.
Start
YES
End
Get the maximum number of iterations
K-means++ algorithm
Calculate the distance from each sample point to its nearest known cluster center.
Collect
Collect
0 Comments
Next page
Recommended for you
More